Publication,
Research,
Docs and Info,
KAMEDA
We implemented a 3D reconstruction system named SCRAPER. We experimentally reconstructed a part of a lecture room in the graduate school of informatics in Kyoto University.
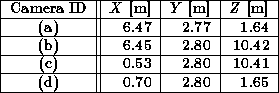
The target space is imaged by four SONY EVI-G20 video cameras fixed at the corners of the lecture room (Figure 2). Table 1 shows the camera position in the room coordinate system.
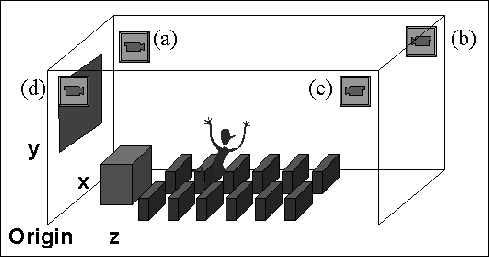
Figure 2: Camera Layout in The Lecture Room
In the experiment, we prepared four image captors and four extractors, and used four SUN Ultra2 200MHz workstations for them. We prepared four 3D composers and assigned them to four SUN Ultra1 170MHz workstations. A scheduler runs on a different workstation. All the workstations are connected on a LAN. The scheduler makes a synchronization among the image captors, the extractors and the 3D composers via 100 base-T Ethernet and 155Mbps ATM LAN. The dynamic region data from the extractors to the 3D composers are transferred on ATM LAN.
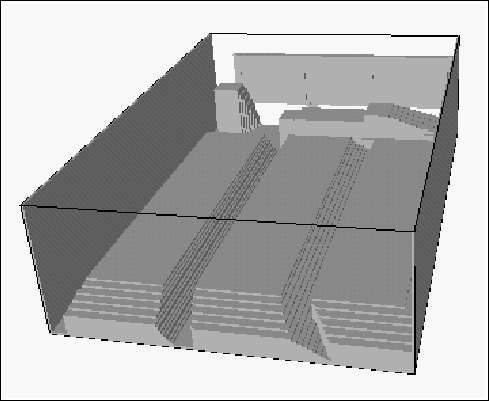
Figure 3 shows SOOS defined by the static object database given in advance. A SOIS from the camera (d) in Figure 2 is shown in Figure 4 for example. These subspace have been calculated before the SCRAPER system starts the reconstruction.
The system reconstructed the the target space which was
imaged more than three cameras. Hence, so a part of the target space was
observed by four cameras, and other part was observed by three
cameras. In the case four cameras imaged the subspace,
n in Equation (2) should be four, and in the other case, if
a camera j could not observe the subspace,
 is the product of
is the product of 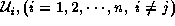 .
Figure 5 displays the target space which is visible by at
least three cameras in the lecture room.
.
Figure 5 displays the target space which is visible by at
least three cameras in the lecture room.
In the experiment, the image captor takes images with
the size of 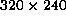 pixels.
The camera which locates the furthest position from the target space
images a cubic subspace of 5 centimeters on a side in the target space
onto one pixel in the captured image.
Therefore, we set the voxel size as a cube of 5 centimeters on a side.
The target space shown in Figure 5 corresponds to 96,769
voxels.
pixels.
The camera which locates the furthest position from the target space
images a cubic subspace of 5 centimeters on a side in the target space
onto one pixel in the captured image.
Therefore, we set the voxel size as a cube of 5 centimeters on a side.
The target space shown in Figure 5 corresponds to 96,769
voxels.
We conducted an experiment to measure the throughput and the latency of
our prototype system. The target space is shown in
Figure 5, and we put a box as a dynamic object whose size
is  .
The result of using four 3D composers are shown in
Table 2. A variable r indicates number of 3D
composers served in each path and s indicates number of
paths in the system. We also conducted an experiment with only one
3D composer just for comparison and its throughput is 2.2
fps and its latency is 1,384 msec.
.
The result of using four 3D composers are shown in
Table 2. A variable r indicates number of 3D
composers served in each path and s indicates number of
paths in the system. We also conducted an experiment with only one
3D composer just for comparison and its throughput is 2.2
fps and its latency is 1,384 msec.

Table 2: Throughput And Latency
The required throughput and latency differ according to applications. One good feature of our method is that we can change the formation suitable to the applications by changing r and s. The result indicates that the case of two 3D composers at two paths is good because the throughput is almost same as four 3D composers at one path and the latency is as short as that of the case of four paths.
We implemented a virtual space viewer which displays the reconstructed real space as a set of voxels in realtime. This viewer displays not only the dynamic objects but also the static objects given to the system in advance, so a user can walk around the lecture room and observe the real-time real space from any viewpoint with little delay.
An example of a captured image is shown in Figure
6 .
Figure 7 shows the reconstructed space
displayed by the viewer. The voxels displayed in the center
corresponds to  , which were transmitted from the SCRAPER
system.
, which were transmitted from the SCRAPER
system.

Figure 6: Video Image from Camera (a)

Figure 7: Reconstructed Space from Other Viewpoint