
Publication,
Research,
Docs and Info,
KAMEDA

We assume that the camera calibration is done in advance and that the initial pose of the human body model is obtained from the method we have proposed in previous paper [2].
Suppose now is time t. As shown in Figure 3, if the double-difference image at time t contains few motion regions (white frames in the figure), the joint values are all fixed as those in the previous frame.
On the other hand, if the double-difference image t contains motion regions(gray frames in the figure), it implies the human body has changed its pose. In this case, the model matching algorithm processes a body object in the model one by one, from the root position to the leafs of the tree structure in the model. We classify a status of the body objects into three modes; moving mode, stationary mode, and occlusion mode. Each body object is labeled with one of the three modes by observing the relationship between the motion regions and the projected region of the body object on the image plane. We calculate joint angles according to the modes of the body objects at each frame(Figure 5). If a body object is hidden by other body objects, it is determined to be in the occlusion mode and the image plane is not referred. To cope with such situation, we introduce inertia constraint such that the body objects in a human body are generally rotated at a constant speed[1].
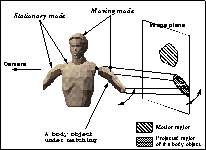
Figure 5: A Body Object under Matching Process